JavaScript 之正则表达式
正则表达式的创建
方法一:new RegExp("pattern"[, "flags"])
其中,pattern 称为模式。flags 称为标志。这种方式可以实现动态改变正则。(运行时编译)
const regText = 'yan';const str = 'xiaoyan';const regexp = new RegExp("["+ regText +"]");
console.log(regexp.test(str));// true注意,使用构造器创建正则时,需要进行转义。原因是 “” 会消耗一个\。
const reg1 = new RegExp("\\w+");const reg2 = /\w+/;
// reg1 和 reg2 作用相同。如果要把特殊字符作为常规字符来使用,也只需要在它前面加个反斜杠。
方法二:/pattern/[flags]
这种方式只能是固定的匹配格式。(编译状态)
const regexp = /\w+/i;正则表达式的实例
// 控制台输入console.dir(/\w+/);
// 输出{ // 表示从哪里开始下一个匹配 lastIndex: 0,
// .号是否要多行匹配 dotAll: false,
// 修饰符 flags: "",
// 全局匹配(与修饰符g 作用相同) global: false,
// 是否启用\d 标志 hasIndices: false,
// 是否忽略大小写(与修饰符i 作用相同) ignoreCase: false,
// 是否要多行搜索 multiline:false,
// 正则表达式的文本 source: "\\w+",
// 是否启用粘性 sticky: false,
// 是否启用Unicode 功能 unicode: false}API
RegExp
regexp.exec(str)
在一个指定字符串中执行一个搜索匹配。
返回值:一个数组或null。
当正则表达式没有标识符g时:
const str = "I love JavaScript";const result = /Java(Script)/.exec(str);
console.dir(result);
// 以一个数组形式返回[ // 完全匹配项 0: "JavaScript",
// 捕获组的匹配项 1: "Script",
// 分组 groups: undefined,
// 匹配的位置 index: 7,
// 输入的字符串 input: "I love JavaScript",
length: 2]当正则表达式有标识符g时:
const str = "I love JavaScript";const exp = /Java(Script)/g;const result = exp.exec(str);
console.dir(exp);
// exp 会记录下紧随匹配项其后的位置在属性 lastIndex 中,// 下次同样使用改表达式时会从位置 lastIndex 开始搜索。{ lastIndex: 17, flags: "g", ……}regexp.test(str)
返回 true/false
检验给定的字符串是否匹配正则表达式。
如果正则表达式带有标志g,匹配将从lastIndex 开始查找,并更新此属性。与exec表现相同
let str = "I love JavaScript";
// 这两个测试相同alert( /love/i.test(str) ); // truealert( str.search(/love/i) != -1 ); // truestring
str.match(regexp)
返回一个数组或null。
-
当正则表达式没有
g标志时,与exec表现相同。 -
当正则表达式带有
g标志时,会将所有匹配项以数组形式返回,而不包含分组和其他详细信息。
const str = "I love JavaScript and Java";
const result = str.match(/Java(Script)?/ig);
console.dir(result);
[ 0: "JavaScript", 1: "Java",
length: 2]str.matchAll(regexp)
返回一个包含所有匹配正则表达式的结果及分组捕获组的迭代器。没有结果时,返回一个空的迭代器。
迭代器不可重用,结果耗尽需要重新调用方法。
RegExp必须是设置了全局模式g的形式,否则会抛出异常TypeError。
注意,这是一个最近添加到 JavaScript 的特性。 旧式浏览器可能需要 polyfills.
let str = '<h1>Hello, world!</h1>';let regexp = /<(.*?)>/g;
let matchAll = str.matchAll(regexp);
console.log(matchAll); // [object RegExp String Iterator],不是数组,而是一个可迭代对象
matchAll = Array.from(matchAll); // 现在返回的是数组
let firstMatch = matchAll[0];console.log( firstMatch[0] ); // <h1>console.log( firstMatch[1] ); // h1console.log( firstMatch.index ); // 0console.log( firstMatch.input ); // <h1>Hello, world!</h1>str.search(regexp)
返回第一个匹配项的位置,如果未找到,则返回 -1
仅能查找第一个普配项,需要查找更多,请用其他方法。
str.split(regexp|substr, limit)
能使用正则表达式或子字符串,作为分隔符来分割字符串。
str.replace(regexp|substr, str|func)
方法返回一个由替换值(replacement)替换部分或所有的模式(pattern)匹配项后的新字符串。
模式可以是一个字符串或者一个正则表达式,
替换值可以是一个字符串或者一个每次匹配都要调用的回调函数。
如果pattern是字符串,则仅替换第一个匹配项
const str = "mo-xiao-yan";const result1 = str.replace("-", "");const result2 = str.replace(/-/g, "");
console.log(result1); // moxiao-yanconsole.log(result2); // moxiaoyan-
如果
replace的第二个参数是要代替的字符串,可以在其中使用一些特殊的字符。符号 替换字符中的操作 $&插入整个匹配项 $插入字符串中匹配项之前的字符串部分 $'插入字符串中匹配项之后的字符串部分 $n如果 n是1到2位的数字,则插入第n个分组的内容$<name>插入带有给定的 name的分组的内容$$插入字符 $示例:
// 交换位置const str = "mo xiaoyan";const result = str.replace(/(mo) (xiaoyan)/, "$2 $1");console.log(result); -
如果
replace的第二个参数是函数,每次匹配都会调用这个函数,并且返回的值将作为替换字符串插入。func(match, p1, p2, ..., pn, offset, input, groups)match- 匹配项。p1, p2, … , pn- 分组的内容(如果有分组的话)。offset- 匹配项的位置。input- 源字符串。groups- 所指定分组的对象。如果正则表达式中没有分组,则只有3个参数:
func(str, offset, input)。
锚点
锚点 ^ 和 $ 属于测试。它们的宽度为零。
^ 会匹配整个文本的开头。
$ 会匹配整个文本的结尾。
const str = "Mary had a little lamb";
console.log( /^Mary/.test(str) ); // trueconsole.log( /lamb$/.test(str) ); // true这两个锚点 ^...$ 放在一起常常被用于测试一个字符串是否完全匹配一个模式。
比如,测试用户的输入是否符合正确的格式。
let goodInput = "12:34";let badInput = "12:345";
let regexp = /^\d\d:\d\d$/;console.log( regexp.test(goodInput) ); // trueconsole.log( regexp.test(badInput) ); // false词边界
词边界 \b 是一种检查,就像 ^ 和 $ 一样。
当正则表达式引擎执行模式遇到 \b 时,它会检查字符串中的位置是否是词边界。
有三种不同的位置可作为词边界:
- 在字符串开头,如果第一个字符是单词字符
\w。 - 在字符串中的两个字符之间,其中一个是单词字符
\w,另一个不是。 - 在字符串末尾,如果最后一个字符是单词字符
\w。
console.log( "Hello, Java!".match(/\bJava\b/) ); // Javaconsole.log( "Hello, JavaScript!".match(/\bJava\b/) ); // null修饰符
在JavaScript中有6个修饰符。
i 使用此修饰符后,在搜索时不区分大小写。
g 搜索时会查找所有匹配项,而不是只搜索第一个。
m 多行模式。仅仅会影响 ^ 和 $ 锚点符的行为。
在多行模式下,它们不仅仅匹配文本的开始与结束,还匹配每一行的开始与结束。
const str =`1st place: Winnie2nd place: Piglet33rd place: Eeyore`;
console.log( str.match(/^\d+/gm) ); // [1,2,33]s 启用 dotAll 模式,允许. 匹配换行符\n 。
console.log( "A\nB".match(/A.B/) ); // null (no match)console.log( "A\nB".match(/A.B/s) ); // A\nB (match!)u 开启完整的 unicode 支持。该修饰符能够修正对于代理对的处理。
一些数学符号、表情等字符,在JavaScript中的长度读取为2,但他们的实际长度为4。
这是因为JavaScript问世时Unicode还没有长度为4的字符。
console.log('😄'.length); // 2console.log('𝒳'.length); // 2默认情况下,正则表达式同样把一个 4 个字节的“长字符”当成一对 2 个字节长的字符。正如在字符串中遇到的情况,这将导致一些奇怪的结果。
修饰符 u 在正则表达式中提供对 Unicode 的支持。
这意味着两件事:
- 4 个字节长的字符被以正确的方式处理。
- Unicode 属性可以被用于查找:
\p{…}。
有了 unicode 属性我们可以查找给定语言中的词,表情、标点符号、字母,特殊字符(引用,货币)等等。
例如,使用 Unicode 属性(\p{L})能够正确匹配任何语言的字母:
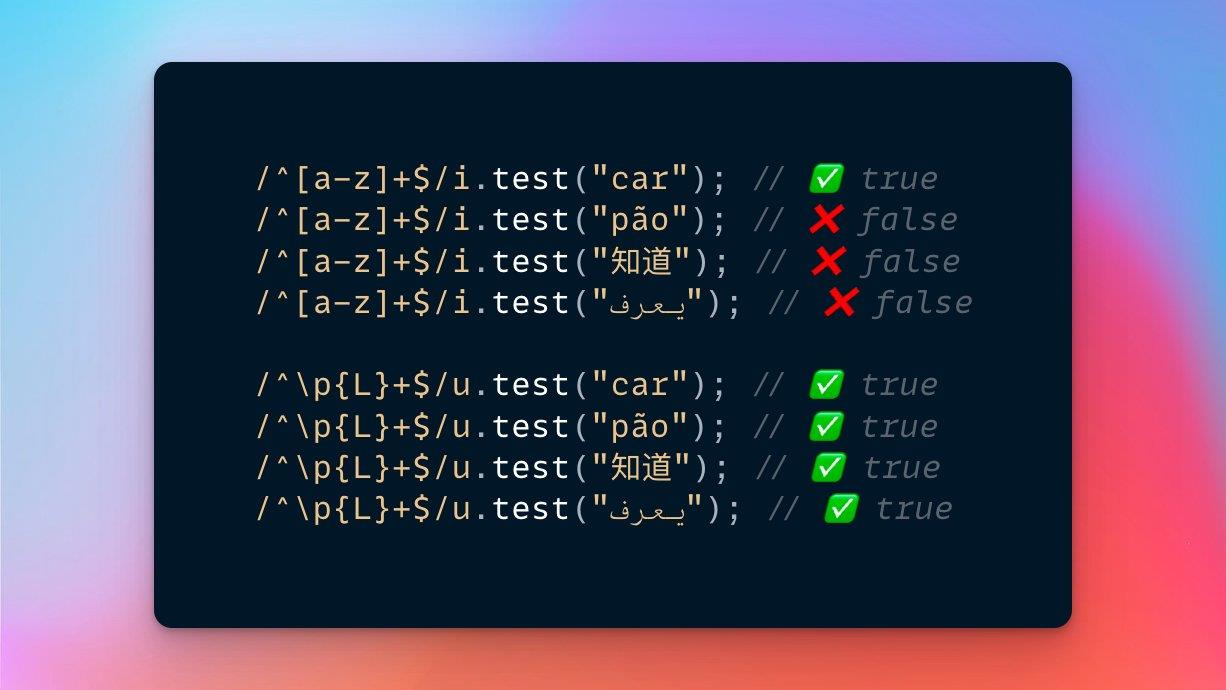
y 开启粘性模式。
标记 y 使 regexp.exec 正好在 lastIndex 位置,而不是在它之前,也不是在它之后。
开启粘性模式后,正则表达式引擎只会搜索lastIndex位置上字符,不会往前搜索,也不会往后搜索。
// 从其中读取变量名const str = 'let varName = "value"';const regexp = /\w+/y;
regexp.lastIndex = 3;console.log( regexp.exec(str) ); // null(位置 3 有一个空格,不是单词)
regexp.lastIndex = 4;console.log( regexp.exec(str) ); // varName(在位置 4 的单词)字符类与反向类
字符类(Character classes) 是一个特殊的符号,匹配特定集中的任何符号。
\d - 匹配数字(0-9)。
\w - 匹配“单字”字符(拉丁字母或数字或下划线 _)。
\s - 匹配空格符号(包括空格,制表符 \t,换行符 \n 和其他少数稀有字符,例如 \v,\f 和 \r)。
反向类对应字符类,使用对应的字母,但是要大写,功能与字符类相反。
\D - 匹配非数字:除 \d 以外的任何字符。
\W - 匹配非空格符号:除 \s 以外的任何字符。
\S - 匹配非单字字符:除 \w 以外的任何字符。
集合与范围
在方括号 […] 中的几个字符或者字符类意味着“搜索给定的字符中的任意一个”。
console.log( "Mop top".match(/[tm]op/gi) ); // []"Mop", "top"]上面例子中的[tm] 被叫做 集合 。它只会匹配对应其中的一个。
范围表示方括号可以包含字符范围。
console.log( /[0-9]/g.test("1234") ); // true如果需要排除某个范围可以使[^……] 来排除范围匹配。
// 查询除了字母,数字和空格之外的任意字符console.log( "alice15@gmail.com".match(/[^\d\sA-Z]/gi) ); // ['@','.']注意,在集合内不需要进行转义。实际上如果不放心加上转义符也是可以的。
量词
最明显的量词便是一对引号间的数字:{n}。
在一个字符(或一个字符类等等)后跟着一个量词,用来指出我们具体需要的数量。
确切的范围数:
\d{5} 表示 5 位的数字,如同 \d\d\d\d\d
console.log( "I'm 12345 years old".match(/\d{5}/) ); // "12345"某个范围数:
console.log( "I'm not 12, but 1234 years old".match(/\d{3,5}/) ); // "1234"console.log( "I'm not 12, but 345678 years old".match(/\d{3,}/) ); // "345678"常用的量词有三种缩写形式。
+ - 代表“一个或多个”,相当于 {1,}。
* - 代表着“零个或多个”,相当于 {0,}。也就是说,这个字符可以多次出现或不出现。
? - 代表“零个或一个”,相当于 {0,1}。换句话说,它使得符号变得可选。
贪婪量词和惰性量词
当我们想搜索出"" 内的内容时,会发现结果并不是我们预期的。
let reg = /".+"/g;let str = 'a "witch" and her "broom" is one';
console.log( str.match(reg) ); // "witch" and her "broom"这是因为正则表达式引擎默认是处于贪婪模式下的。
在贪婪模式下,量词都会尽可能地重复多次。
贪婪搜索
正则表达式引擎的搜索算法:
- 对于字符串中的每一个字符
- 用这个模式来匹配这个字符
- 若无法匹配移至下一个字符
接下来,让我们详细说明一下模式 ".+" 是如何进行搜索工作的。
-
该模式的第一个字符是一个引号
"。正则表达式引擎会逐个字符地检查
a "witch" and her "broom" is one字符串是否符合模式的第一个字符,如果不符合就检查下一个字符,直到匹配模式的第一个字符。 -
检测到了
"后,引擎就尝试去匹配模式中的下一个字符(这里是.)。
-
因为量词
+,模式中的点(.)将会重复地匹配所有字符,只有在移至字符串末尾时才停止匹配。
-
由于字符串已经匹配完了,并且模式中还有结尾的一个
"没有进行匹配,所以这时正则表达式引擎会进行回溯。即+匹配次数 -1 ,当+的匹配次数正好对应字符串最后一个引号时,正则表达式引擎就结束匹配。 -
于是我们得到了
"witch" and her "broom"。
惰性模式
懒惰模式中的量词与贪婪模式中的是相反的。它想要“重复最少次数”。
我们能够通过在量词之后添加一个问号 '?' 来启用它。
所以匹配模式变为 *? 或 +?,甚至将 '?' 变为 ?? 。
const reg = /".+?"/g;const str = 'a "witch" and her "broom" is one';
console.log( str.match(reg) ); // [witch, broom]这是因为引擎在执行模式中的量词时,会判断模式中的下一个字符(这里是 "),与字符串中的下一个字符是否相同,若相同就返回匹配项。
代替方法
const reg = /"[^"]+"/g;const str = 'a "witch" and her "broom" is one';
console.log( str.match(reg) ); // [witch, broom]捕获组
模式的一部分可以用括号括起来 (...)。这称为“捕获组(capturing group)”。
这有两个影响:
-
它允许将匹配的一部分作为结果数组中的单独项。
const str = '<h1>Hello, world!</h1>';const tag = str.match(/<(.*?)>/);console.log(tag); // ["<h1>", "h1"] ,其中 h1 为捕获组的匹配项。 -
如果我们将量词放在括号后,则它将括号视为一个整体。
console.log( 'Gogogo now!'.match(/(go)+/i) ); // "Gogogo"
当有多个捕获组时:
const str = '<span class="my">';const regexp = /<(([a-z]+)\s*([^>]*))>/;const result = str.match(regexp);
console.log(result[0]); // <span class="my">console.log(result[1]); // span class="my"console.log(result[2]); // spanconsole.log(result[3]); // class="my"虽然我们可以通过,像result[1] 、result[2] 、… result[n] ,这样的方式获取捕获组的匹配项。但这样并不够优雅。
我们还可以通过 ?<name> 来给捕获组命名,获得匹配项的时候,只需要 groups.name 即可。
let dateRegexp = /(?<year>[0-9]{4})-(?<month>[0-9]{2})-(?<day>[0-9]{2})/;let str = "2022-07-02";let groups = str.match(dateRegexp).groups;
console.log(groups.year); // 2022console.log(groups.month); // 07console.log(groups.day); // 02注意,有多少个 (…) 就会有多少个捕获组匹配项,即使没有相应的匹配结果。没有相应的匹配结果的捕获组结果等于undefined 。
非捕获组
模式的一部分可以用括号括起来 (?:...)。这称为“非捕获组”。
有时我们需要括号才能正确应用量词,但我们不希望它们的内容出现在结果中。
let str = "Gogogo John!";
// ?: 从捕获组中排除 'go'let regexp = /(?:go)+ (\w+)/i;let result = str.match(regexp);
console.log( result[0] ); // Gogogo John(完全匹配)console.log( result[1] ); // Johnconsole.log( result.length ); // 2反向引用
我们不仅可以在结果或替换字符串中使用捕获组 (...) 的内容,还可以在模式本身中使用它们。
按编号反向引用: \N 在模式中引用一个组,其中 N 是组号。
let str = `He said: "She's the one!".`;let regexp = /(['"])(.*?)\1/g;
console.log( str.match(regexp) ); // "She's the one!"由于捕获组可以给其命名,同样也可以根据命名进行反向引用。
按命名反向引用: \k<name>
let str = `He said: "She's the one!".`;let regexp = /(?<quote>['"])(.*?)\k<quote>/g;
console.log( str.match(regexp) ); // "She's the one!"选择
选择是正则表达式中的一个术语,实际上是一个简单的“或”。
在正则表达式中,它用竖线 | 表示。
let reg = /html|php|css|java(script)?/gi;let str = "First HTML appeared, then CSS, then JavaScript";
console.log( str.match(reg) ); // ['HTML', 'CSS', 'JavaScript']注意: gr(a|e)y 严格等同 gr[ae]y。
前瞻断言与后瞻断言
-
前瞻肯定断言
语法:
x(?=y),它表示“仅在后面是y的情况匹配x”。let str = "1 turkey costs 30€";console.log( str.match(/\d+(?=€)/) ); // 30 (正确地跳过了单个的数字 1) -
前瞻否定断言
语法:
x(?!y),意思是 “查找x, 但是仅在不被y跟随的情况下匹配成功”。let str = "2 turkeys cost 60€";console.log( str.match(/\d+(?!€)/) ); // 2(正确地跳过了价格) -
后瞻肯定断言
语法:
(?<=y)x, 匹配x, 仅在前面是y的情况。let str = "1 turkey costs $30";console.log( str.match(/(?<=\$)\d+/) ); // 30 (跳过了单个的数字 1) -
后瞻否定断言
语法:
(?<!y)x, 匹配x, 仅在前面不是y的情况。let str = "2 turkeys cost $60";console.log( str.match(/(?<!\$)\d+/) ); // 2 (跳过了价格)注意:一般来说,环视断言括号中(前瞻和后瞻的通用名称)的内容不会成为匹配到的一部分结果。
但是如果我们想要捕捉整个环视表达式或其中的一部分,那也是有可能的。
只需要将其包裹在另加的括号中。
let str = "1 turkey costs 30€";let reg = /\d+(?=(€))/; // € 两边有额外的括号console.log( str.match(reg) ); // [30, €]
灾难性回溯
有些正则表达式看上去很简单,但是执行起来耗时非常非常非常长,甚至会导致 JavaScript 引擎「挂起」。
let regexp = /^(\d+)*$/;let str = "012345678901234567890123456789!";
// 会耗费大量时间console.log( regexp.test(str) );ps:如果理解上面的正则表达式引擎搜索算法再参考贪婪搜索步骤推理即可知道挂起原因。
实际上导致挂起的原因就是:查找所需要尝试的排列组合次数太多。准确的说,如果这数字长度是 n ,则共有 2^n^-1 种方式去排列组合。
如何解决?
-
重写正则表达式,减少排列组合次数。
let regexp = /^(\w+\s)*\w*$/;let str = "An input string that takes a long time or even makes this regex to hang!";console.log( regexp.test(str) ); // false -
禁止量词的回溯。
现代正则表达式引擎支持占有型量词,它们也被成为“原子捕获分组(atomic capturing groups)” – 能够在括号内禁止回溯。
不幸的是,JavaScript 并不支持它。
-
使用前瞻断言来防止回溯。
let regexp = /^((?=(\w+))\2\s?)*$/;let str = "An input string that takes a long time or even makes this regex to hang!";console.log( regexp.test(str) ); // false,执行得很快!